Kimi K2.5: La guida definitiva per usarlo come Coding Agent (e perché non puoi hostarlo da solo)
Analisi approfondita di Kimi K2.5 di Moonshot AI: architettura MoE, integrazione come coding agent tramite OpenCode, confronto provider API, costi reali del self-hosting e strategie operative per sviluppatori e freelance nel 2026.

L'inizio del 2026 ha segnato un punto di svolta nell'ecosistema dell'intelligenza artificiale generativa. Mentre i giganti della Silicon Valley continuano a proporre modelli sempre più chiusi e costosi, Kimi k2.5 di Moonshot AI ha dimostrato che l'approccio open-weights può competere con GPT-5.2 e Claude 4.5 Opus, offrendo capacità agentiche superiori in scenari specifici come la navigazione web e lo sviluppo assistito.
Ma c'è un elefante nella stanza che molti contenuti promozionali ignorano: seppur tecnicamente "open-weights", Kimi k2.5 non è affatto self-hostable per il 99% degli sviluppatori e delle piccole imprese. I requisiti hardware per far girare questo colosso da 1,04 trilioni di parametri superano abbondantemente i 600-700GB di RAM, rendendo necessario un investimento infrastrutturale che oscilla tra i 15.000€ e i 20.000€ solo per le GPU.
Questo articolo ti guiderà attraverso ciò che davvero serve sapere su Kimi k2.5: come integrarlo efficacemente come coding agent tramite OpenCode e altri strumenti compatibili, come sfruttare i provider API per testarlo gratuitamente o a costi contenuti, e perché dovresti abbandonare immediatamente l'idea di hostarlo in locale a meno che tu non gestisca un datacenter.
Cos'è Kimi k2.5 e perché dovresti interessartene nel 2026
Kimi k2.5 rappresenta l'evoluzione naturale della serie Kimi, lanciata da Moonshot AI nell'ottobre 2023 come semplice chatbot con finestra di contesto da 128.000 token. A gennaio 2026, il modello è diventato un orchestratore agentico multimodale capace di coordinare fino a 100 sub-agenti in parallelo, gestendo flussi di lavoro complessi che arrivano a 1.500 chiamate a strumenti coordinate.
L'Evoluzione di Kimi: Da Chatbot a Orchestratore Agentico
Lancio del Kimi Chatbot originale con contesto da 128k token
Rilascio di Kimi K1.5
con tecniche RLHF avanzate
Presentazione di Kimi K2 Base
Primo MoE da 1 trilione di parametri
Introduzione di Kimi K2 Thinking
Per ragionamento step-by-step
Debutto di Kimi k2.5
Con multimodalità nativa e Agent Swarm
La caratteristica distintiva di Kimi k2.5 non risiede solo nelle dimensioni del modello, ma nella sua architettura Mixture-of-Experts (MoE) che consente di attivare solo 32 miliardi di parametri per ogni token generato, pur disponendo di un arsenale complessivo di 1,04 trilioni di parametri distribuiti su 384 esperti specializzati.
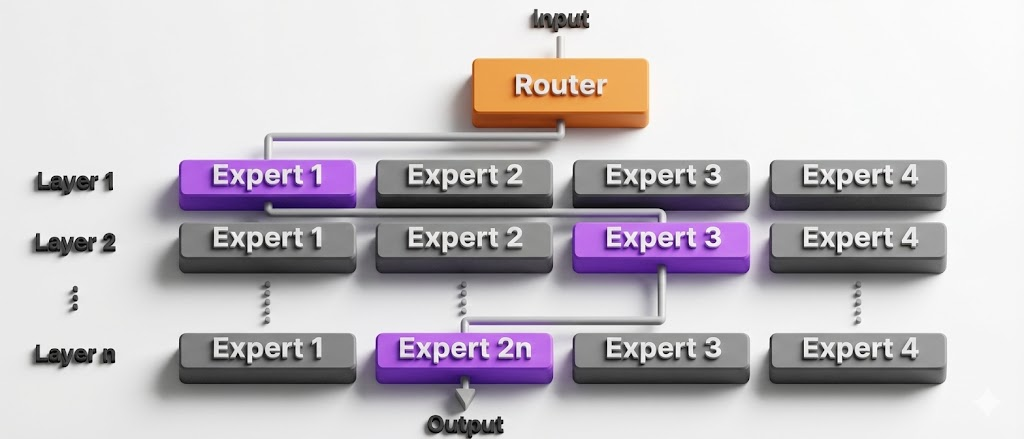
Perché l'architettura MoE cambia le regole del gioco
L'architettura MoE non è una novità assoluta nell'intelligenza artificiale, ma l'implementazione di Moonshot AI presenta alcune caratteristiche tecniche degne di nota. Il modello è composto da 61 strati neurali, di cui 60 sono strati MoE e uno è uno strato denso condiviso. Per ogni token in input, un sistema di routing intelligente seleziona 8 esperti su 384, garantendo che solo la parte rilevante della rete neurale venga consultata.
Questo meccanismo offre due vantaggi concreti per chi sviluppa applicazioni AI:
- Efficienza di inferenza: grazie all'attivazione sparsa, il modello può offrire prestazioni comparabili a modelli proprietari mantenendo costi computazionali inferiori. I provider API possono quindi proporre tariffe competitive senza sacrificare la qualità dell'output.
- Specializzazione dei domini: durante l'addestramento, diversi gruppi di esperti si sono specializzati in ambiti distinti come sintassi del codice, logica matematica, comprensione linguistica o analisi visiva. Questo significa che quando chiedi al modello di debuggare un componente React, vengono attivati prevalentemente gli esperti "coding-oriented", mentre per un task di ricerca web si attivano esperti specializzati nella navigazione e nell'estrazione di informazioni.
L'integrazione del meccanismo Multi-head Latent Attention (MLA) riduce il consumo di banda della memoria del 40-50%, permettendo la gestione di finestre di contesto fino a 256.000 token anche su hardware di fascia medio-alta. Questa caratteristica rende Kimi k2.5 particolarmente adatto per applicazioni RAG che richiedono l'elaborazione di documentazione tecnica massiva.
La verità scomoda: perché NON puoi hostare Kimi k2.5 in self-hosting
Molti articoli celebrano l'approccio "open-weights" di Kimi k2.5, lasciando intendere che chiunque possa scaricare i pesi del modello e farlo girare sul proprio hardware. Tecnicamente è vero. Praticamente è una chimera per la stragrande maggioranza degli sviluppatori e delle piccole imprese.
Per eseguire Kimi k2.5 in locale, anche nella versione quantizzata, servono risorse computazionali che superano di gran lunga le capacità di qualsiasi workstation professionale. Ecco i numeri concreti:
Versione quantizzata a 4-bit (Q4_K_M): richiede circa 400 GB di VRAM. Per ottenere questa capacità, dovresti assemblare un cluster di 10-12 schede NVIDIA RTX 3090 o 4090 da 24GB ciascuna, oppure investire in 3-4 NVIDIA A100 da 80GB. Il costo delle sole GPU si aggira tra i 15.000€ e i 20.000€ per hardware usato, senza contare l'infrastruttura di raffreddamento, alimentazione e networking necessaria per far comunicare le schede in parallelo.
Versione quantizzata a 2-bit (Q2_K): la qualità dell'output degrada significativamente, ma i requisiti scendono "solo" a 230 GB di VRAM. Rimane comunque una configurazione fuori portata per la maggior parte degli sviluppatori.
La quantizzazione estrema (2-bit) può compromettere seriamente la qualità del ragionamento e della generazione di codice. Se l'obiettivo è usare Kimi k2.5 come coding agent professionale, questa opzione è sconsigliata anche se riducesse i requisiti hardware.
L'unica eccezione: Apple Silicon con RAM unificata
Esiste un'unica soluzione "accessibile" per chi vuole sperimentare con modelli di questa dimensione in locale: i Mac Studio con chip M2 o M3 Ultra dotati di 192GB di RAM unificata. L'architettura Apple Silicon condivide la stessa memoria tra CPU e GPU, permettendo di caricare modelli molto grandi anche senza VRAM dedicata.
Questa configurazione costa circa 6.000€-7.000€ e consente di eseguire versioni quantizzate di Kimi k2.5, ma con performance molto lente (pochi token al secondo). È una soluzione adatta per sperimentazione e test locali, non per uso produttivo.

Di fronte a questi numeri, la scelta razionale per sviluppatori freelance e piccole imprese è chiara: utilizzare i provider API che offrono accesso a Kimi k2.5 con tariffe competitive e infrastruttura gestita. Nel prossimo capitolo analizzeremo nel dettaglio i provider più convenienti e come scegliere quello giusto in base al tuo caso d'uso specifico.
Confronto provider API: dove testare Kimi k2.5 gratuitamente o a costi contenuti
Il panorama dei provider API per Kimi k2.5 nel primo trimestre del 2026 è estremamente frammentato, offrendo opportunità concrete di arbitraggio dei costi per chi sa navigare tra le diverse offerte. La scelta del partner infrastrutturale non deve basarsi esclusivamente sul prezzo di listino, ma sulla natura specifica del carico di lavoro: task input-intensivi, generazione massiva di output o flussi agentici a lungo termine.
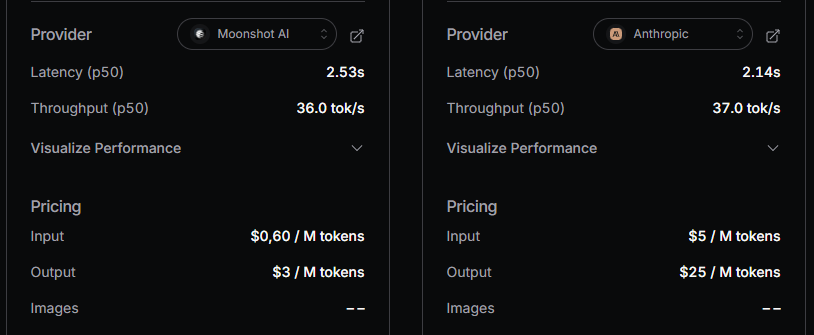
DeepInfra: il leader per input e latenza
DeepInfra si è consolidato come il provider di riferimento per chi cerca il costo minimo per milione di token di input. Con una tariffa di $0.45 per 1M di token di input, DeepInfra risulta il 25% più economico rispetto alla piattaforma ufficiale di Moonshot AI per le chiamate standard.
I test di latenza (Time to First Token - TTFT) dimostrano che DeepInfra, insieme a Together.ai, offre la reattività più alta del mercato con soli 0.33 secondi per ricevere il primo token. La velocità di generazione si attesta sui 65 token al secondo, rendendo questo provider ideale per applicazioni che richiedono risposte rapide e interattive come chatbot di assistenza clienti o sistemi di analisi email in tempo reale.
Quando scegliere DeepInfra: task con grandi volumi di input (analisi di documentazione, processing di codebase estese, RAG con contesti massivi) e necessità di risposte rapide.
Parasail e Fireworks: ottimizzazione per generazione e throughput
Per i task che richiedono una generazione massiva di testo — come la scrittura di lunghi report tecnici, documentazione automatica o sviluppo software con output estesi — Parasail emerge come il vincitore economico. Con un costo di output di $2.50 per milione di token, Parasail offre un risparmio del 17% rispetto ai $3.00 di Moonshot.
Fireworks segue a ruota con prestazioni di throughput eccezionali, raggiungendo i 195 token al secondo, la velocità più alta registrata tra i provider benchmarkati. Questa performance lo rende particolarmente adatto per scenari di generazione batch o applicazioni che richiedono risposte molto lunghe in tempi ridotti.
Quando scegliere Parasail/Fireworks: sviluppo software assistito, generazione di contenuti lunghi, task di refactoring massivo di codebase.
Moonshot AI: il dominio del context caching per RAG enterprise
La piattaforma ufficiale di Moonshot AI adotta una strategia di prezzo difensiva focalizzata sulla fedeltà enterprise. Sebbene i prezzi base siano più alti ($0.60 input / $3.00 output), Moonshot offre la tariffa più bassa del settore per i Cache Hit: solo $0.10 per milione di token.
Questo rende Moonshot AI la scelta strategica per applicazioni di Retrieval-Augmented Generation (RAG) dove il medesimo contesto massivo (documentazione tecnica, archivi legali, knowledge base aziendali) viene riutilizzato migliaia di volte al giorno. Il risparmio accumulato sui cache hit può compensare ampiamente il costo superiore delle chiamate "fredde".
| Provider | Prezzo Input (1M token) | Prezzo Output (1M token) | Input cached | Note strategiche |
|---|---|---|---|---|
| DeepInfra | $0.45 | $2.80 | $0.225 | Leader per input e latenza (TTFT 0.33s) |
| Parasail | $0.50 | $2.50 | N/D | Leader per costi di generazione |
| Fireworks | $0.60 | $2.50 | N/D | Massima velocità (195 t/s) |
| Moonshot | $0.60 | $3.00 | $0.10 | Ideale per Enterprise RAG |
| Together AI | $0.50 | $2.80 | N/D | Focus su affidabilità e SLA |
Sul mercato asiatico è presente anche questo provider: Novita AI, con un input price per 1M di $0.60 e un output price di $3.00. Sostanzialmente identico a Moonshot.
Come testare Kimi K2.5 gratuitamente con OpenCode
Uno dei modi più efficaci per sperimentare con Kimi k2.5 senza costi iniziali è utilizzare OpenCode, un'interfaccia CLI che permette di interagire con il modello direttamente dal terminale e di integrarlo come coding agent nei propri flussi di lavoro.
OpenCode supporta la compatibilità con endpoint OpenAI, rendendo semplicissima la configurazione con qualsiasi provider che offra questa interfaccia standardizzata. Molti provider offrono crediti gratuiti iniziali o tier free per testare i modelli:
- Together.ai: offre crediti gratuiti per nuovi utenti
- Novita AI: piano free tier con limiti generosi per testing
- Moonshot AI: accesso diretto tramite kimi.com con possibilità di testare la modalità Agent Swarm in beta
Ho scritto un articolo dedicato che parla di kimi.com, della modalità d’uso della loro piattaforma e di come ottenere il piano Allegretto per un mese al costo di circa 2 euro. Lo trovi qui.
Nel prossimo capitolo vedremo nel dettaglio come configurare OpenCode e integrare Kimi k2.5 come coding agent all'interno di VS Code e altri ambienti di sviluppo.
Come usare Kimi k2.5 come coding agent: integrazione con OpenCode e VS Code
La vera potenza di Kimi k2.5 emerge quando lo si integra come coding agent autonomo all'interno del proprio ambiente di sviluppo. Grazie alla compatibilità con l'ecosistema OpenAI e alla multimodalità nativa, il modello può agire come un vero e proprio "pair programmer" capace di leggere file, eseguire test, analizzare visivamente componenti UI e correggere bug in autonomia.
Configurazione base con OpenCode CLI
OpenCode è uno strumento CLI open-source che permette di interfacciare Kimi k2.5 (e altri modelli) direttamente dal terminale. La configurazione richiede pochi passaggi:
Una volta configurato, OpenCode permette di eseguire task agentici direttamente da terminale, come analizzare intere codebase, generare test automatici o refactorare componenti.
Integrazione in VS Code tramite Cline
Per un'esperienza di sviluppo completamente integrata, Clineè l'estensione VS Code di riferimento per trasformare Kimi k2.5 in un assistente di coding contestuale. Cline supporta nativamente provider compatibili con l'API OpenAI, rendendo l'integrazione di Kimi k2.5 immediata.
- Installa l'estensione Cline dal marketplace di VS Code
- Apri le impostazioni di Cline e seleziona "OpenAI Compatible" come provider
- (Opzionale) Crea un file .clinerules nella root del progetto per definire istruzioni personalizzate
- Testa l'integrazione chiedendo a Cline di analizzare un file del progetto
- Inserisci il Base URL del provider scelto (es. https://api.deepinfra.com/v1/openai per DeepInfra)
- Configura il Model ID come moonshotai/kimi-k2.5
Parametri critici per la modalità "Thinking"
Kimi k2.5 supporta due modalità operative: Instant e Thinking. La modalità Thinking è fondamentale per task complessi che richiedono ragionamento multi-step, come debugging di architetture complesse o ottimizzazione di algoritmi.
Per attivare correttamente questa modalità via API, è essenziale rispettare parametri di campionamento specifici. Impostazioni errate possono degradare drasticamente la qualità dell'output, portando il modello a fornire risposte superficiali o incoerenti.
La modalità Thinking genera internamente una "catena di ragionamento" che precede la risposta finale. Questo processo richiede token aggiuntivi, quindi è importante impostare un max_tokens sufficientemente alto — generalmente tra 16.000 e 32.768 token — per non troncare il processo di reasoning.
Una delle caratteristiche più potenti di Cline è la possibilità di definire regole personalizzate che guidano il comportamento del modello all'interno del progetto. Creando un file .clinerules nella root del repository, puoi istruire Kimi k2.5 a seguire convenzioni specifiche, pattern architetturali o flussi di lavoro agentici.
Questa configurazione trasforma Kimi k2.5 da semplice assistente a un vero e proprio membro del team che segue le tue best practice e ottimizza il proprio workflow in base al contesto del progetto.
E in Github Copilot Chat?
Si. Puoi integrarlo anche tramite Github e usufruire delle mille opportunità che l’attuale versione di questa estensione ti da tra cui: creazione di sub agents, accesso agli MCP, lettura dettagliata della workspace e tanto altro. Github Copilot insieme agli altri IDE in corsa cerca di avvicinarsi sempre di più al leader del mercato che è senza dubbio Cursor.
In ogni caso dalla libreria modelli attualmente Github Copilot prevede la possibilità di aggiungere modelli custom direttamente da un provider terzo (ma anche da Ollama per esempio, in locale) e quindi è possibile agganciare Kimi K2.5 tramite OpenRouter
Non devi per forza passare usare le api di intermediazione di OpenRouter. Puoi anche configurare la tua chiave Moonshot nelle impostazioni del tuo account dal web e indicare tramite il selettore predisposto di direttore le richieste usando la tua API. Attenzione: bisogna verificare se questo può avere un impatto rilevante in latency (p50) per ciò che devi fare.
Agent Swarm: quando e come sfruttare l'orchestrazione parallela
Una delle caratteristiche distintive di Kimi k2.5 è la tecnologia Agent Swarm, che segna il passaggio dall'IA sequenziale all'IA parallela e collaborativa. Comprendere quando e come attivare questa modalità può fare la differenza tra un'applicazione efficiente e una che spreca risorse computazionali.
Anatomia di uno sciame: orchestratore e sub-agenti
In modalità Agent Swarm, Kimi k2.5 agisce come un supervisore che analizza il compito macroscopico dell'utente e lo scompone in sotto-task atomici. Il modello può istanziare autonomamente fino a 100 sub-agenti specializzati che lavorano in parallelo, gestendo flussi di lavoro che arrivano fino a 1.500 chiamate a strumenti coordinate.
Questa architettura permette una riduzione del tempo di esecuzione dei compiti complessi di circa 4.5 volte rispetto ai sistemi a singolo agente come GPT o Claude.
Scenario d'Uso Pratico - Agent Swarm per Ricerca Competitiva
Obiettivo: Analizzare 30 competitor nel settore SaaS B2B e produrre un report comparativo con pricing, features e posizionamento di mercato.
Orchestrazione Tradizionale (singolo agente): Il modello visita i siti uno alla volta, estrae informazioni, le sintetizza. Tempo stimato: 3-4 ore.
Orchestrazione Agent Swarm:
- L'orchestratore crea 30 sub-agenti, uno per competitor
- Ogni agente esegue in parallelo: scraping del sito, estrazione pricing, analisi features
- Un agente "synthesizer" aggrega i risultati in un unico report strutturato
- Tempo stimato: 15-20 minuti
Il risparmio di tempo è drammatico, ma comporta un aumento nel numero di token consumati (più agenti = più chiamate API). La scelta di attivare Agent Swarm va quindi valutata in base al valore del tempo risparmiato rispetto al costo addizionale.
Quando attivare Agent Swarm (e quando evitarlo)
Attiva Agent Swarm quando:
- Devi elaborare grandi volumi di dati strutturalmente simili (es. 50 siti web, 100 file CSV, analisi multi-repository)
- Il task è facilmente parallelizzabile senza dipendenze sequenziali
- Il tempo di esecuzione è critico (es. analisi pre-riunione, report urgenti)
- Stai lavorando su ricerca multi-fonte che richiede sintesi di fonti eterogenee
Evita Agent Swarm quando:
- Il task richiede ragionamento sequenziale profondo (es. debugging di bug complessi dove ogni step dipende dal precedente)
- Stai lavorando su codice singolo o refactoring di componenti piccoli
- Il budget di token è limitato e il tempo non è critico
- La natura del task è esplorativa e non beneficia di parallelizzazione
Agent Swarm è attualmente in fase beta su kimi.com e tramite le API ufficiali. La tecnologia è alimentata dal Parallel-Agent Reinforcement Learning (PARL), un metodo di addestramento che insegna al modello come coordinare efficacemente gli agenti senza conflitti di contesto.
La multimodalità nativa di Kimi k2.5, addestrata su 15 trilioni di token misti testo-visione, abilita capacità di sviluppo front-end senza precedenti nel panorama dei coding agent.
Dal design al codice: conversione automatica di mockup
Il modello può "vedere" mock-up di design, screenshot o registrazioni video e convertirli in codice funzionale React, Vue o Tailwind con una precisione spaziale millimetrica. Questa capacità elimina gran parte del lavoro manuale di traduzione design-to-code che storicamente ha richiesto ore di lavoro tedioso.
Workflow tipico con Visual Coding:
- Il designer fornisce un Figma export o uno screenshot del componente desiderato
- Kimi k2.5 analizza visivamente il layout, i colori, le proporzioni, il tipografia
- Il modello genera il codice JSX/TSX completo con classi Tailwind appropriate
- Il codice viene testato automaticamente e, se necessario, il modello itera per correggere discrepanze
Una delle innovazioni più significative è l'autonomia nel debugging visivo. Kimi k2.5 può generare un componente UI, ispezionare visivamente il proprio output per identificare discrepanze di allineamento, colore o spaziatura rispetto al design originale e iterare autonomamente fino a ottenere un risultato "pixel-perfect".
Questo ciclo di feedback riduce drasticamente il tempo che uno sviluppatore freelance deve dedicare a rifiniture estetiche banali, permettendo di concentrarsi sulla logica di business e sull'architettura.
La capacità di visual debugging richiede che il modello possa effettivamente "vedere" il risultato del codice generato. Per sfruttare appieno questa funzionalità, è necessario configurare un ambiente di preview automatico o fornire manualmente screenshot iterativi al modello.
Benchmark reali: quando Kimi K2.5 supera GPT-5.2 e Claude Opus 4.5
Nelle valutazioni indipendenti condotte nel primo trimestre del 2026, Kimi k2.5 ha dimostrato di aver colmato, e in certi casi superato, il gap con modelli proprietari come GPT-5.2 e Claude 4.5 Opus, specialmente nei benchmark che misurano l'autonomia agentica e la navigazione web.
Dall'analisi dei dati emerge che mentre GPT-5.2 rimane il leader nel ragionamento matematico astratto (AIME 2025), Kimi k2.5 domina nelle attività "mondane" di ricerca e navigazione (BrowseComp), staccando Claude Opus 4.5 di quasi 13 punti percentuali.
Questo lo rende lo strumento di elezione per freelance e team che gestiscono workflow di:
- Ricerca di mercato e competitive analysis
- SEO research e content gap analysis
- Data gathering da fonti web eterogenee
- Automazione di task ripetitivi che richiedono navigazione multi-step
Nel coding puro (SWE-Bench Verified), Kimi k2.5 si attesta leggermente sotto GPT-5.2 e Claude Opus 4.5, ma la differenza è marginale (circa 4 punti percentuali) e spesso compensata dalla velocità superiore e dai costi inferiori quando si utilizzano provider ottimizzati come DeepInfra o Parasail.
Nonostante l'eccellenza nell'agentic search, Kimi k2.5 è stato notato per la sua verbosità eccessiva. Nelle valutazioni di Artificial Analysis, il modello ha generato circa 89 milioni di token per l'Intelligence Index, una cifra molto superiore alla media di 13 milioni della sua classe. Questo è un fattore da considerare attentamente nel calcolo dei costi di output, specialmente per applicazioni con elevati volumi di richieste.)
Per mitigare questo problema, è consigliabile:
- Utilizzare system prompts espliciti che richiedono concisione
- Implementare post-processing per filtrare contenuto ridondante
- Scegliere provider con tariffe output competitive come Parasail ($2.50/1M token)
Casi d'uso reali per freelance e piccole imprese
L'adozione strategica di Kimi K2.5 può trasformare radicalmente il modello di business di freelance e piccole imprese tecnologiche, permettendo di competere con agenzie molto più grandi grazie all'efficienza agentica.
Automazione della ricerca competitiva
Un freelance specializzato in consulenza strategica può costruire workflow automatizzati che:
- Monitorano quotidianamente i siti dei competitor
- Estraggono pricing, feature updates e comunicati stampa
- Sintetizzano i dati in report esecutivi settimanali
- Inviano alert automatici in caso di cambiamenti significativi
Questo tipo di servizio, che tradizionalmente richiederebbe 5-10 ore settimanali di lavoro manuale, può essere completamente automatizzato con Agent Swarm e mantenuto con un costo di poche decine di dollari al mese in chiamate API.
Sviluppo front-end accelerato
Uno sviluppatore freelance specializzato in interfacce può sfruttare il visual coding per:
- Convertire Figma exports in componenti React/Vue funzionali in minuti
- Implementare design system completi partendo da mockup visivi
- Debugging automatico di discrepanze tra design e implementazione
- Generazione di varianti responsive senza intervento manuale
Questo riduce drasticamente i tempi di delivery, permettendo di gestire più progetti in parallelo o di offrire tariffe più competitive mantenendo margini elevati.
Per chi lavora nel content marketing, Kimi K2.5 può orchestrare:
- Analisi gap di contenuto rispetto ai competitor top-ranking
- Ricerca automatica di trending topics e opportunità di ranking
- Generazione di content briefs strutturati basati su analisi SERP
- Ottimizzazione di articoli esistenti per intent matching
L'Agent Swarm permette di analizzare contemporaneamente decine di articoli competitor, estrarre pattern comuni e identificare opportunità differenzianti in una frazione del tempo che richiederebbe un'analisi manuale.
FigmaMCP - L'alleato perfetto
Se opportunatamente configurato può essere sicuramente utilizzato da uno degli agenti in orchestrazione per accelerare di molto i tempi di traduzione da design Figma a codice. Maggiori dettagli qui help.figma.com - Guide to the Figma MCP server
Strategia di adozione: come integrare Kimi K2.5 nel tuo stack tecnologico
Per massimizzare il ritorno sull'investimento nell'adozione di Kimi K2.5, è essenziale costruire una strategia multi-provider che sfrutta le peculiarità di costo e performance di ciascun fornitore.
Invece di legarsi a un singolo provider, implementa un layer di routing che invia automaticamente le richieste al provider ottimale in base alla natura del task:
Task RAG con contesto riutilizzabile → Moonshot AI (per sfruttare il cache hit a $0.10/1M) Task input-intensivi con risposte brevi → DeepInfra (input a $0.45/1M e latenza minima) Generazione massiva di codice/documentazione → Parasail (output a $2.50/1M) Task che richiedono massima velocità → Fireworks (195 token/s)
Questo approccio può ridurre i costi operativi del 30-50% rispetto all'uso di un singolo provider, mantenendo performance ottimali per ogni categoria di task.
Implementa sistemi di logging che tracciano:
- Costo per task (input + output tokens)
- Tempo di esecuzione (latency + generation time)
- Qualità dell'output (feedback umano o metriche automatiche)
Questi dati permettono di identificare pattern e ottimizzare progressivamente la scelta del provider e i parametri di chiamata API.
- Crea account su 2-3 provider diversi (DeepInfra, Parasail, Moonshot) per testare differenze di performance
- Configura OpenCode CLI e testa task semplici da terminale
- Integra Cline in VS Code e definisci .clinerules per il tuo progetto principale
- Implementa un workflow Agent Swarm per un task ripetitivo del tuo business
- Documenta un case study dell'uso di Kimi k2.5 per posizionarti come early adopter
Il futuro è nell'orchestrazione, non nel possesso
Kimi K2.5 ha dimostrato che il futuro dell'intelligenza artificiale applicata al business non risiede nel possesso di infrastruttura costosa, ma nella capacità di orchestrare intelligentemente risorse distribuite.
Mentre il self-hosting rimane un miraggio economico per la stragrande maggioranza degli sviluppatori (richiedendo investimenti di 15.000€-20.000€ solo in hardware), l'accesso tramite provider API democratizza l'uso di modelli di frontiera, permettendo anche a freelance e piccole imprese di competere con le capacità tecnologiche di organizzazioni molto più grandi.
La combinazione di un'architettura Mixture-of-Experts da un trilione di parametri, multimodalità nativa e tecnologia Agent Swarm pone Kimi K2.5 in una posizione di forza in scenari specifici come navigazione web, ricerca competitiva e sviluppo front-end assistito, pur mantenendo un gap rispetto a GPT-5.2 e Claude Opus 4.5 in task di ragionamento matematico puro e coding complesso.
La raccomandazione strategica per il 2026 è chiara: non investire in hardware per self-hosting. Costruisci invece competenza nell'integrazione API multi-provider, nell'uso di strumenti come OpenCode e Cline, e nella configurazione di workflow agentici che massimizzano l'efficienza del tuo tempo. In un mondo dove l'IA è diventata una commodity, il vero vantaggio competitivo risiede nell'intelligenza con cui queste risorse vengono orchestrate.
Vuoi approfondire come integrare Kimi k2.5 nel tuo flusso di lavoro specifico? Contattami per una consulenza personalizzata sull'adozione di coding agent e strategie di AI orchestration per il tuo business.
Grazie per aver letto questo articolo