Intelligenza Artificiale
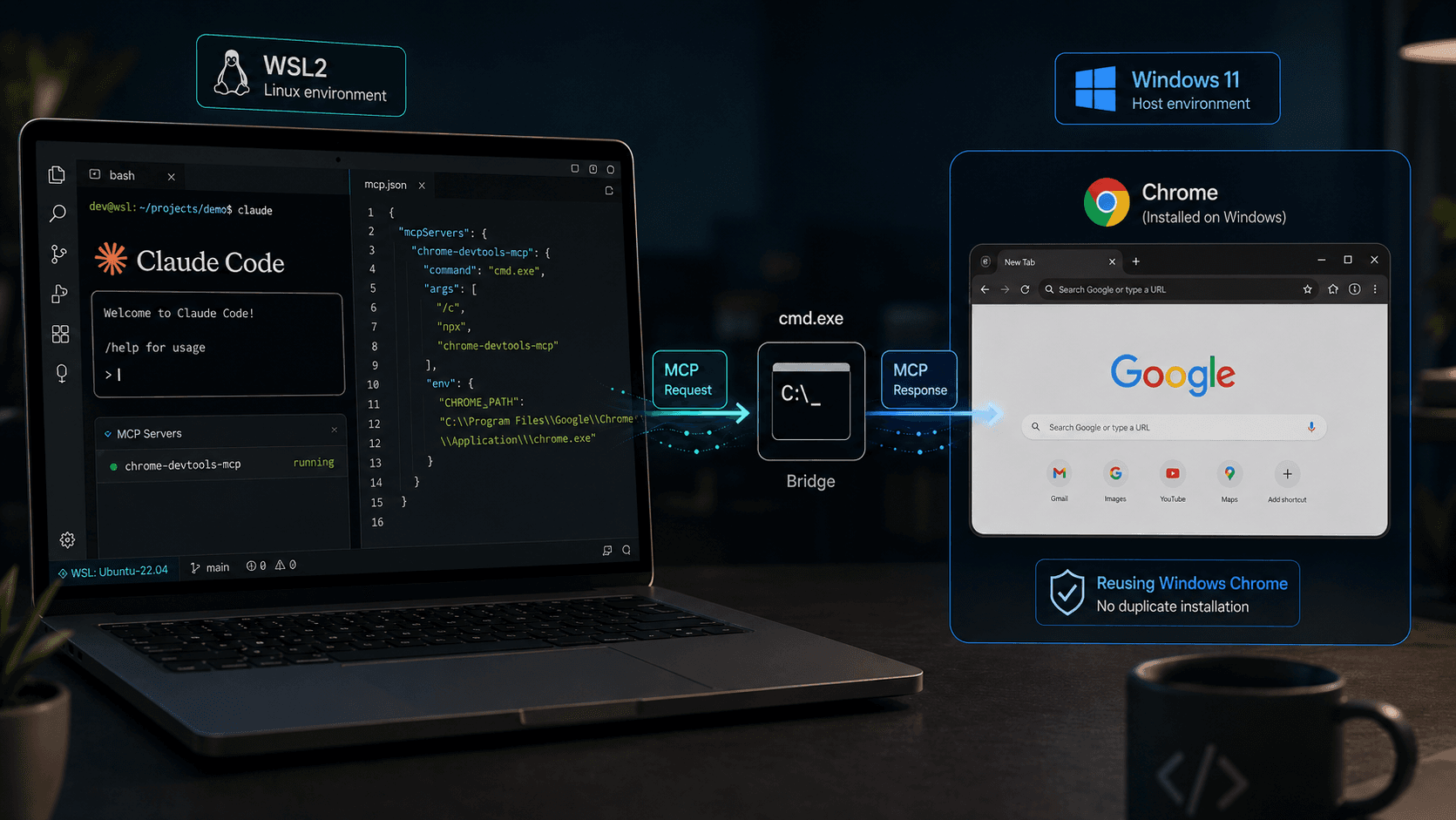
Chrome DevTools MCP su WSL2: Claude Code senza uscire da Linux
Configurare chrome-devtools-mcp con Claude Code da WSL2 riusando il Chrome di Windows tramite cmd.exe, senza installazioni duplicate o setup manuali a ogni sessione.

