Bandi pubblici su misura: notifiche automatiche per la tua azienda
Come monitorare i bandi pubblici italiani con notifiche Telegram automatiche, sfruttando l'API gratuita di ANAC. Case study e soluzione su misura.

Tutto è nato una sera in cui stavo controllando un bando per un cliente sul cruscotto pubblico di ANAC, dati.anticorruzione.it. Mentre cliccavo i filtri e guardavo le tabelle aggiornarsi, ho aperto la network tab del browser per curiosità. È lì che ho scoperto che il cruscotto è in realtà l'interfaccia front-end di un'API Superset completamente pubblica, gratuita, e accessibile via HTTP a chiunque sappia dove guardare.
Da quel momento è diventato evidente che la stessa infrastruttura nata per fare trasparenza e analisi anticorruzione poteva essere riutilizzata in modo radicalmente diverso: come canale di lead generation per qualsiasi azienda che voglia partecipare a bandi pubblici in Italia, senza pagare 80-150 euro al mese di abbonamento a una piattaforma SaaS verticale.
Il risultato finale è bandi-watch: un watcher Python che gira due volte al giorno su una mia VPS DigitalOcean, costa circa 5 euro al mese di infrastruttura, e manda notifiche su Telegram quando trova bandi che corrispondono ai criteri di un cliente specifico. In questo articolo racconto come funziona, ma soprattutto perché funziona meglio dei SaaS generici per la maggior parte delle aziende italiane.
Il problema vero: la classificazione caotica dei bandi
Prima di parlare di codice e API c'è un problema strutturale della Pubblica Amministrazione italiana che vale la pena spiegare, perché è esattamente la ragione per cui i SaaS generici di ricerca bandi lasciano sul tavolo una percentuale enorme di opportunità rilevanti.
Quando un funzionario della PA pubblica un bando deve classificarlo con uno o più codici CPV (Common Procurement Vocabulary), il sistema europeo di tassonomia degli acquisti pubblici. Il problema è che lo stesso bando reale, materialmente identico, può essere classificato in 4 o 5 modi completamente diversi a seconda di chi lo redige e di quali sono le sue priorità interpretative.
Pensiamo a un caso pratico: un bando per la realizzazione del nuovo sito web di un museo civico. È un esempio che si vede continuamente sul cruscotto BDNCP. Quel bando può finire classificato in modi molto diversi:
| Profilo del funzionario | Codice CPV scelto | Logica interpretativa |
|---|---|---|
| Dirigente IT | 72413000 | Lo legge come progettazione siti web, asse tecnico |
| Assistente settore cultura | 92500000 | Lo legge come servizi connessi a musei |
| Addetto comunicazione | 79340000 | Lo legge come servizi pubblicitari/marketing |
| Funzionario gare | 79822500 | Lo classifica per la componente grafica |
Tutti questi codici descrivono lo stesso lavoro. Solo che il funzionario che ha redatto il documento, in base alla sua sensibilità e al regolamento del proprio ente, ha scelto un punto di vista diverso. Tutti hanno ragione e tutti hanno torto allo stesso tempo.
Il risultato pratico è che se imposti un alert su una piattaforma SaaS basato solo sul CPV 72413000, ti perderai sistematicamente i bandi classificati negli altri tre modi, anche se per la tua agenzia di sviluppo web sono identicamente rilevanti. La copertura mancante non è marginale: nei dati osservati sull'agenzia di comunicazione siciliana di cui parlo dopo, la sola ricerca per CPV avrebbe perso circa il 30-40% dei match utili.
La conseguenza è che una ricerca seria di bandi non può mai basarsi su un solo asse. Servono almeno tre layer di filtraggio combinati e mappati sui bisogni specifici dell'azienda che li userà. È una cosa che un SaaS generico non può fare per natura: deve servire chiunque, mentre tu hai bisogno di un filtro modellato su di te.
Cos'è BDNCP e perché vale oro per il business development
La Banca Dati Nazionale dei Contratti Pubblici (BDNCP) è il sistema centralizzato gestito da ANAC dove confluiscono per legge tutti i procedimenti di gara con CIG attivo, cioè con Codice Identificativo Gara assegnato. Ogni stazione appaltante in Italia, dai piccoli comuni alle agenzie nazionali, è obbligata a registrare lì i propri bandi.
Il dataset più rilevante per la nostra applicazione si chiama BANDI_IN_CORSO ed è esposto come tabella all'interno della dashboard Superset di ANAC. Per ogni bando contiene, fra le altre cose: il CIG, l'oggetto del bando in testo libero, la denominazione e il codice fiscale dell'amministrazione appaltante, la provincia, la sezione regionale, l'importo del lotto, il o i codici CPV, il tipo di procedura di scelta del contraente, la data di pubblicazione e un flag che indica se è finanziato da fondi PNRR.
Per il business development questo significa accesso strutturato e quasi in tempo reale a quello che i tuoi clienti potenziali pubblici stanno comprando, in tutta Italia, con un livello di dettaglio che nessun database commerciale privato può eguagliare. La query "tutti gli enti regionali siciliani che hanno appaltato comunicazione istituzionale negli ultimi 6 mesi sopra i 30k euro" è fattibile in un singolo HTTP request.
I limiti del dataset
Va detto chiaramente cosa il dataset non copre, perché altrimenti non si capisce la portata del lavoro residuo.
Il primo limite riguarda la soglia di affidamento. Per i contratti sotto la soglia comunitaria di 140.000 euro per servizi e forniture, il Codice dei Contratti consente alle amministrazioni di procedere con affidamento diretto o con procedure semplificate basate su manifestazione di interesse, in cui l'ente pubblica un avviso esplorativo, riceve adesioni dagli operatori economici interessati e poi seleziona uno o più candidati a cui chiedere preventivo. Questi avvisi pre-affidamento non passano da BDNCP: vivono sui portali di trasparenza dei singoli enti o sulle loro piattaforme di e-procurement, che spesso sono diverse tra loro.
Il secondo limite è normativo: l'articolo 77 del Codice dei Contratti prevede consultazioni preliminari di mercato in cui le amministrazioni interpellano gli operatori per definire le specifiche tecniche di una futura gara. Anche queste sono fuori dal CIG e fuori da BDNCP.
È un limite reale ma non invalidante: a fine articolo mostro come trasformare questo gap in opportunità commerciale concreta, usando i dati post-affidamento per fare profilazione strategica delle stazioni appaltanti e iscrizione proattiva agli albi fornitori.
Sul lato tecnico il dataset è esposto con un row limit di 1000 record per query, sufficiente per quasi tutte le saved search ben filtrate, e l'API non supporta cursori per paginare oltre.
Anatomia dell'API Superset di ANAC
L'endpoint da chiamare è https://dati.anticorruzione.it/superset/explore_json/. Il datasource è identificato dalla stringa 81__table, che corrisponde alla tabella BANDI_IN_CORSO. La query è una POST con payload application/x-www-form-urlencoded, in cui il campo form_data contiene un JSON serializzato con la struttura tipica di Superset:
I filtri possono essere di tipo SIMPLE (operatori ==, <=, >=, fra altri) oppure di tipo SQL libero, e sotto il cofano vengono tradotti in clausole WHERE su un engine Dremio. La risposta è un JSON con un campo data.records che contiene la lista dei bandi.
Da notare due quirks dell'engine sotto al cofano. Il primo: Dremio non supporta ILIKE nelle espressioni SQL libere, quindi per le ricerche case-insensitive sull'oggetto del bando bisogna usare il pattern LOWER(oggetto_bando) LIKE LOWER('%keyword%'). Funzionalmente equivalente, ma se non lo sai te ne accorgi solo dopo un paio di 500 in console. Il secondo: quando il rowcount è zero, il campo data arriva come null invece che come dict vuoto, va gestito esplicitamente nel parsing.
I tre layer di filtraggio per battere la classificazione caotica
Tornando al problema iniziale: una ricerca che voglia coprire davvero le opportunità rilevanti per un'azienda deve combinare almeno tre direzioni di attacco diverse, ognuna pensata per intercettare un pezzo del comportamento eterogeneo dei funzionari.
Lista di prefissi CPV in OR fra loro, scelti perché coprono le categorie ufficiali in cui il tuo lavoro dovrebbe essere classificato secondo il vocabolario europeo. Per un'agenzia di comunicazione i prefissi rilevanti sono ad esempio 7934 (servizi pubblicitari e di marketing), 79416 (pubbliche relazioni), 7995 (organizzazione eventi), 9211 (produzione video). Questo layer cattura i bandi redatti da funzionari che seguono il manuale.
Tutti e tre i layer si combinano in AND fra loro per definire una saved search. Ed è qui che si vede perché un SaaS generico non può funzionare bene: la matrice delle keyword e degli exclude va costruita a mano, leggendo i bandi reali del settore del cliente e capendo dove sono i suoi falsi positivi. È un lavoro di un paio di giorni per cliente, ma una volta fatto il sistema gira da solo per anni.
Due ostacoli tecnici che nessuno ti dice
Mettere insieme la prima query in locale è facile, ma ci sono due ostacoli che ti blindano subito quando provi a portare il sistema in produzione su un runner cloud.
Il primo è il WAF. ANAC protegge la sua dashboard con un firewall applicativo (Volterra/F5) che valuta euristicamente le richieste in arrivo. Una richiesta GET con form_data lungo nella query string da un IP datacenter di GitHub o di una cloud generica viene tipicamente bloccata con HTTP 403, anche se localmente da browser funziona perfetto. Le contromisure efficaci sono due, da applicare insieme: usare la libreria curl_cffi con impersonate Chrome, che replica il TLS fingerprint di un browser reale, e spostare la query da GET a POST aprendo prima la pagina della dashboard per scaldare la sessione e raccogliere i cookie.
Il secondo ostacolo, già accennato, è il workaround Dremio per la case-insensitivity sulle keyword. Anziché usare ILIKE (non supportato in SQL libero) ricorri a LOWER su entrambi i lati del confronto:
Nessuno di questi due workaround è documentato sul portale di ANAC. Li ho scoperti solo dopo qualche giro di trial and error in CI. È il tipo di tempo che il cliente finale non vuole pagare due volte.
Architettura del watcher
L'architettura tecnica è volutamente minimale, ottimizzata per costare poco e non richiedere mantenimento.
- Linguaggio: Python 3.12 con requests, curl_cffi, PyYAML
- Storage: SQLite locale, single file db.sqlite
- Scheduler: GitHub Actions con cron schedulati
- Compute: runner self-hosted su VPS DigitalOcean da 5€/mese
- Notifiche: bot Telegram via Bot API
Il workflow GitHub gira due volte al giorno (06:00 e 16:00 UTC, cioè 8 e 18 italiane d'estate) per le saved search di tipo realtime, e una volta a settimana il sabato mattina per il digest delle saved search di tipo weekly. Lo schedule è configurato come cron nel file .github/workflows/watch.yml:
La scelta del runner self-hosted invece dei runner GitHub-hosted gratuiti è motivata proprio dal WAF: un IP DigitalOcean di Francoforte ha un fingerprint più "consumer" rispetto al pool dei runner condivisi GitHub, e il firewall applicativo lo lascia passare con meno frizione. In più, sulla VPS posso schedulare anche altri job senza pagare nulla in più.
Riconciliazione, persistenza e auto-onboarding Telegram
Il problema operativo principale di un watcher schedulato è ricordarsi cosa ha già notificato. Per evitare di spammare il cliente ogni 6 ore con gli stessi bandi, il sistema usa un database SQLite con tre tabelle principali:
La logica è: ogni run carica i match della saved search, fa upsert in bandi, aggiorna bando_search_match segnando come scaduti i match precedenti non più visti, identifica i CIG mai notificati e manda solo quelli. Se la stessa gara matcha tre saved search diverse, viene notificata una volta per ciascuna ma con contesto separato.
Per persistere il database fra run consecutivi senza pagare un servizio cloud, sfrutto una tecnica un po' creativa: salvo db.sqlite come artifact GitHub (retention 30 giorni) e in più lo committo a un branch orfano del repository chiamato db-state. Al run successivo recupero quel file con un git checkout origin/db-state -- db.sqlite. Funziona, è gratis, e ha l'effetto collaterale piacevole di farti uno storico versionato del DB se mai dovesse servire.
Bonus operativo: il sistema gestisce l'onboarding di Telegram in modo autonomo. Non serve configurare manualmente il TELEGRAM_CHAT_ID, basta impostare una passcode con TELEGRAM_SUBSCRIBE_CODE e mandare al bot un messaggio /start <codice>. Al primo run, il watcher legge getUpdates, trova la chat che ha mandato la passcode, salva il chat_id in una tabella app_state, e da lì in poi notifica solo quella chat. Comodo per consegnare il setup a un cliente non tecnico senza fargli toccare la console.
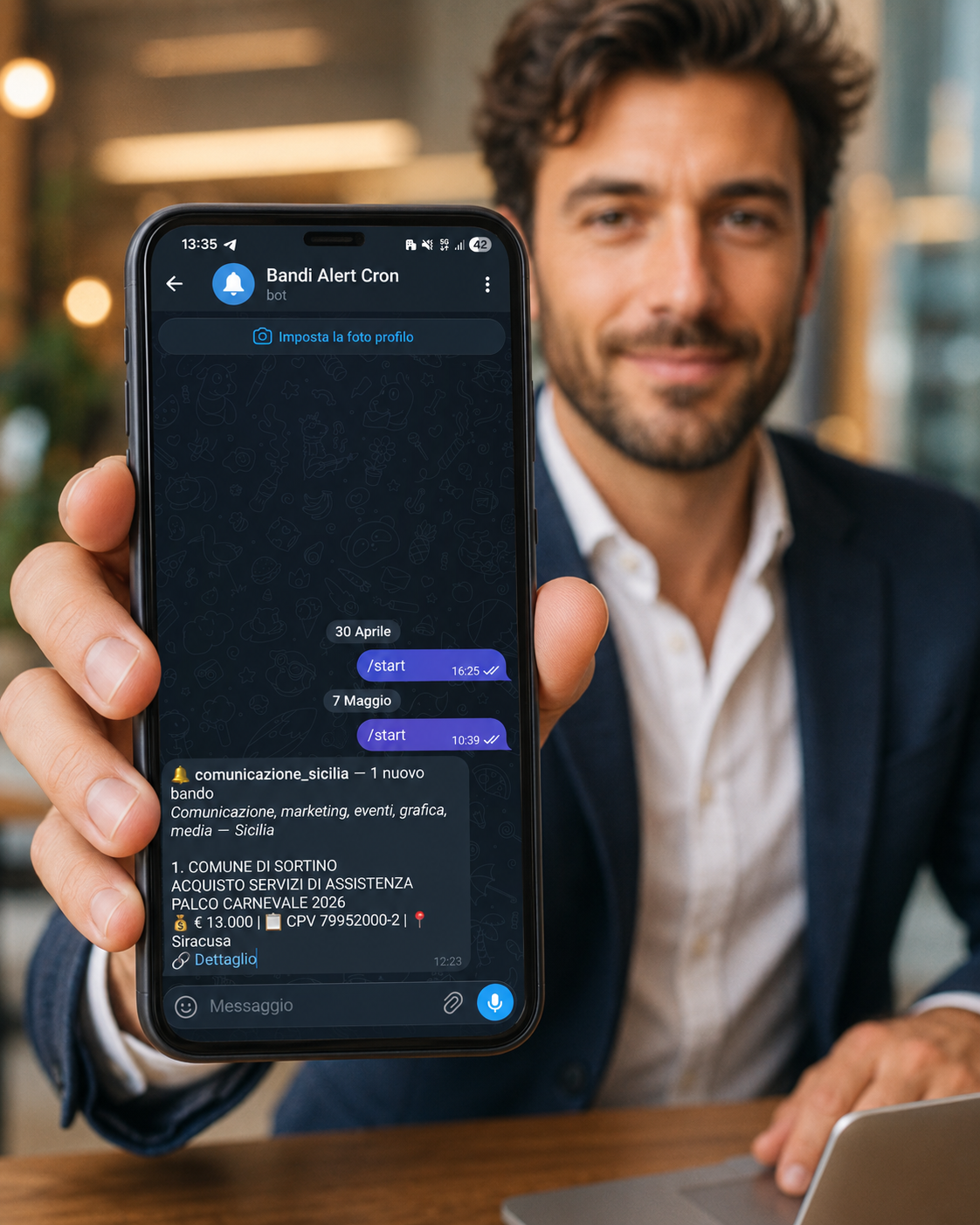
Realtime contro digest settimanale
Non tutte le saved search hanno la stessa filosofia operativa. Alcune sono nicchie precise dove ogni match è una potenziale opportunità da chiamare entro 24-48 ore (gare regionali a volume basso, finestre di partecipazione strette). Altre sono ricerche larghe a livello nazionale che servono più per tenere il polso del mercato che per partecipare immediatamente.
Quando usare delivery realtime
Saved search a volume atteso basso, settoriali o regionali, dove un nuovo match merita attenzione e azione rapida. Nel caso pratico dell'agenzia di comunicazione siciliana sono le ricerche su CPV stretti limitati alla Sicilia. Volume tipico: 0-3 nuovi match per run.
Quando usare delivery weekly
Saved search con scope nazionale o keyword larghe, che generano molti match al giorno e diventerebbero rumore se notificate subito. Vanno in digest accumulato che parte sabato mattina, quando la PA è ferma e c'è il tempo per leggere con calma. Nel caso pratico sono le ricerche di comunicazione su tutta Italia con importo sopra i 50.000 euro.
La regola pratica che uso: se mi aspetto più di 5 nuovi match a settimana per saved search, va in weekly. Se meno, realtime.
Caso pratico: agenzia di comunicazione siciliana
Per concretizzare il discorso ho applicato il sistema a un cliente reale: un'agenzia di comunicazione siciliana che organizza eventi territoriali, fa ufficio stampa istituzionale e gestisce campagne di promozione culturale. Ho mappato il suo profilo in 7 saved search totali, tre realtime e quattro weekly.
Le tre realtime sono mirate sulla Sicilia: una su CPV stretti di comunicazione/marketing/eventi/grafica/video (cattura i bandi classificati ortodossamente), una su keyword in oggetto della sfera comunicazione/PR/grafica (cattura i bandi con CPV inaspettati ma con segnali chiari nel testo), e una su keyword web e software per i bandi misti dove serve un sito o una webapp dentro un progetto più grande.
Le quattro weekly sono a scope nazionale, mirate a partnership o subappalto per gare grosse: comunicazione e media a livello Italia con importo sopra 50k, web e software custom a livello Italia, keyword web/gamification/software, e una saved search su eventi e festival nazionali (disabilitata di default e attivabile manualmente nei periodi di maggior interesse).
Tutta la configurazione vive in un file YAML versionato in repo. Una nuova saved search si aggiunge in 10 righe:
Il watcher offre anche una modalità --explore per testare una saved search prima di metterla in produzione: esegue la query, stampa i primi 30 risultati, ma non scrive niente in DB e non manda notifiche. Serve per tunare le keyword e gli exclude osservando i match reali, prima di fare commit. È il modo in cui ho costruito le 7 saved search del cliente: una giornata di trial and error sul dataset reale, leggendo i match e raffinando gli elenchi.
Bonus strategico: dal monitoraggio reattivo al CRM proattivo
Torniamo al limite della sotto-soglia: tutti i contratti sotto i 140k euro che vengono affidati con manifestazione di interesse non sono visibili nel dataset prima dell'aggiudicazione. Apparente sconfitta. In realtà, una volta che l'affidamento si conclude, il record entra in BDNCP con il CIG, il vincitore, l'importo e la stazione appaltante. Da quel momento è un dato pubblico interrogabile con la stessa API.
Questo apre un secondo caso d'uso che vale almeno quanto il primo: la profilazione strategica delle stazioni appaltanti. Mining sui dati storici di tutti gli affidamenti del tuo settore per identificare gli enti che spendono ricorrentemente nella tua categoria, capire quali sono le loro fasce di importo medie, chi hanno usato in passato e decidere su quali enti vale la pena fare iscrizione proattiva all'albo fornitori.
Il punto chiave è che gli albi fornitori sono il pool da cui i funzionari pescano quando devono fare manifestazioni di interesse e affidamenti diretti. Se sei nell'albo del Comune X e il Comune X ha aggiudicato negli ultimi 3 anni cinque servizi di comunicazione da 60-80k euro ciascuno, la probabilità che il prossimo invito all'esplorazione finisca nella tua casella di posta è molto alta. Se non sei nell'albo, sei invisibile per definizione.
Estrazione storica
Query sul dataset BDNCP per tutti gli affidamenti chiusi del tuo settore negli ultimi 24-36 mesi.
Profilazione enti
Ranking delle stazioni appaltanti per frequenza di acquisto, fascia media di importo e affinità con la tua offerta concreta.
Iscrizione albi fornitori
Per i top 20-30 enti compili la procedura di iscrizione all'albo, dichiarando le categorie merceologiche e i requisiti.
Inviti a manifestazioni
Quando l'ente ha bisogno di un servizio sotto-soglia, pesca dall'albo e ti manda l'invito a presentare offerta o manifestazione.
Affidamento diretto
L'incarico arriva senza essere mai passato dal cruscotto BDNCP nella fase pre-aggiudicazione. Cerchio chiuso.
Il sistema bandi-watch può essere configurato per eseguire periodicamente questa estrazione storica e produrre un rapporto in CSV o markdown con la lista degli enti da considerare. Ed è qui che il valore commerciale di una soluzione su misura supera quello di qualsiasi piattaforma SaaS di ricerca bandi: i SaaS ti vendono visibilità sui bandi attivi, una soluzione custom ti dà anche la mappa strategica per posizionarti dove andranno a pescare i prossimi lavori sotto-soglia.
Costi reali e CTA finale
Riassumendo i costi infrastrutturali di un setup come quello descritto e mettendoli a confronto con un abbonamento SaaS verticale tipico:
| Voce | Soluzione su misura | SaaS verticale tipico |
|---|---|---|
| Costo infrastruttura | 5 €/mese (DigitalOcean) | 0 € |
| Abbonamento software | 0 € | 80-150 €/mese |
| Setup iniziale | Una tantum (chiavi in mano) | 0 € |
| Personalizzazione filtri | Totale, su misura | Preset e limitata |
| Notifiche Telegram | Native | Spesso solo email |
| Profilazione storica enti | Inclusa | Non inclusa |
| Manutenzione filtri | A richiesta | Non disponibile |
| Lock-in vendor | Nessuno (codice tuo) | Totale |
Per una PMI che oggi spende 1500-2000 euro l'anno in abbonamenti SaaS verticali, il punto di pareggio rispetto a un setup chiavi in mano si raggiunge nei primi mesi. E da lì in poi il sistema diventa un asset interno tuo, con codice di proprietà, filtri tuoi e nessun lock-in. Inoltre, qualsiasi servizio in abbonamento per la ricerca dei bandi richiede oltre al costo diretto, un costo interno legato al tempo che verrà impiegato per interagire con lo strumento e imparare a personalizzarlo.
Se quello che hai letto risuona con il tuo settore e vuoi capire se ha senso anche per la tua azienda, posso costruirti un sistema su misura partendo dai tuoi clienti tipo, dai tuoi codici CPV di riferimento e dalle keyword che caratterizzano i bandi rilevanti per te. Compreso il caso d'uso CRM proattivo per gli affidamenti sotto-soglia.
Grazie per aver letto questo articolo