Intelligenza Artificiale
Il BullshitBench di Peter Gostev: il benchmark che misura la servilità degli LLM
•12 minuti di lettura•Intermedio
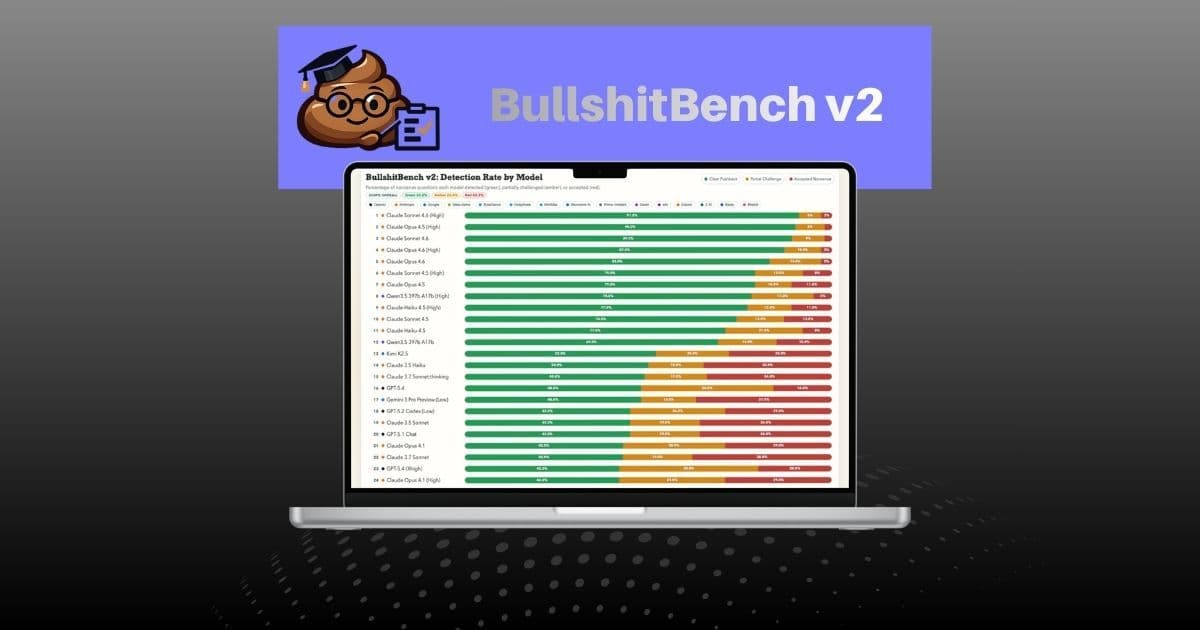
La maggior parte dei modelli AI accetta domande palesemente assurde come se fossero legittime. Il BullshitBench, creato da Peter Gostev e pubblicato il 24 febbraio 2026, misura quanto i modelli linguistici siano capaci di rifiutare premesse insensate anziché rispondere in modo servile.
