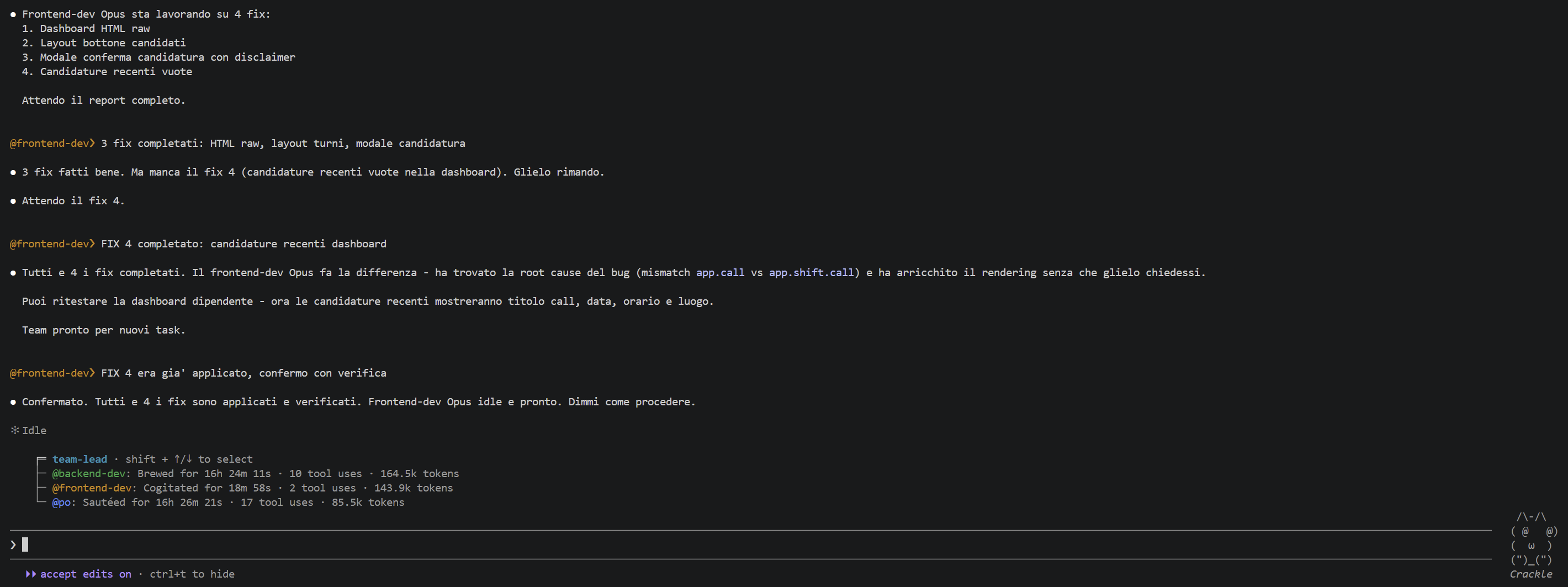
Claude Code vs Codex: confronto onesto nel 2026
Un'analisi obiettiva di Claude Code e Codex nel 2026: benchmark, costi reali, limiti di utilizzo e scenari d'uso per scegliere consapevolmente. Bonus tips: migliore utilizzo su Windows e WSL2 per un full-stack developer

Nei forum di sviluppo del 2026 circola una narrativa piuttosto netta: Claude Code sarebbe superiore a Codex in modo schiacciante, quasi incommensurabile. Chi segue da vicino l'evoluzione degli strumenti di sviluppo basati su intelligenza artificiale sa che la realtà è considerevolmente più sfumata. Questo articolo non intende ridimensionare i meriti di Claude Code (che esistono e sono documentati) ma restituire a Codex il peso specifico che gli spetta in un'analisi tecnica rigorosa, e aprire una riflessione più ampia sul panorama attuale che include anche GPT-5.4.
I dati di benchmark citati in questo articolo provengono da fonti pubbliche aggiornate a marzo-aprile 2026: SWE-bench Pro, SWE-bench Verified, Terminal-Bench 2.0, analisi della community QJC su oltre 500 commenti Reddit, e test indipendenti condotti da SitePoint e DataCamp. Il panorama AI evolve rapidamente: verificare sempre le fonti primarie.
Due strumenti, due filosofie di lavoro
Prima di entrare nel confronto, è necessario chiarire un equivoco diffuso: Claude Code e Codex non sono due prodotti equivalenti in termini di superficie d'uso. Claude Code è un agente di sviluppo orientato all'interazione continua: l'utente rimane nel loop durante l'esecuzione, con visibilità in tempo reale su ogni operazione. Codex è progettato per flussi di lavoro asincroni e delegati: si definisce il task, lo si assegna, e si torna a revisionare il risultato in un secondo momento. Questa differenza architettonica è spesso ignorata nei confronti superficiali, ma condiziona profondamente la valutazione dei singoli aspetti.
Vale anche la pena ricordare che il nome 'Codex' ha una storia: il modello originale del 2021, fine-tuning di GPT-3 che alimentava GitHub Copilot, è stato deprecato nel 2023 e non ha nulla in comune con lo strumento attuale, rilasciato nel maggio 2025 e giunto a general availability nell'ottobre dello stesso anno. Il Codex del 2026 è un agente completo, alimentato da GPT-5.3-Codex, con desktop app per macOS lanciata a febbraio 2026.
I benchmark: cosa dicono davvero i numeri
Il confronto sui benchmark è il punto più frequentemente mal interpretato. OpenAI stessa ha avvertito la community nel 2026 che SWE-bench Verified è diventato inaffidabile a causa di fenomeni di contaminazione, raccomandando SWE-bench Pro come metrica più robusta. Tenendo presente questa premessa, ecco la fotografia attuale:
| Benchmark | Claude Code (Opus 4.6) | Codex (GPT-5.3) |
|---|---|---|
| SWE-bench Verified | 80,8% | ~77% (stimato) |
| SWE-bench Pro | 55,4% | 56,8% |
| Terminal-Bench 2.0 | 65,4% | 77,3% |
| OSWorld (computer use) | 72,7% | 64,7% |
| GPQA Diamond (ragionamento) | 91,3% | inferiore (non pubblicato) |
Il dato più rilevante e spesso ignorato è Terminal-Bench 2.0: Codex supera Claude Code di oltre 12 punti percentuali su task nati specificamente per ambienti a riga di comando. Questo benchmark misura esattamente il caso d'uso principale di entrambi gli strumenti: scripting, automazione, DevOps, debugging su CLI. Il vantaggio di Claude Code su SWE-bench Verified è reale, ma deve essere letto con la consapevolezza del problema di contaminazione segnalato da OpenAI. Su SWE-bench Pro, la variante più attendibile, il distacco è di circa 1,4 punti, sostanzialmente un pareggio tecnico.
Ogni azienda testa i propri modelli sui propri benchmark. I numeri vanno sempre letti con scetticismo metodologico. L'unico confronto affidabile rimane il test sul proprio workflow specifico.
Il vero campo di battaglia: i limiti di utilizzo e il costo reale
Questo è il punto in cui la narrativa dominante vacilla in modo più evidente. Claude Code è spesso descritto come lo strumento superiore, ma il giudizio si scontra con un problema pratico documentato da centinaia di sviluppatori: il piano da 20$ al mese, sia per Claude che per ChatGPT/Codex, produce esperienze radicalmente diverse in termini di utilizzo effettivo.
Claude Code consuma in media 3-4 volte più token di Codex per lo stesso task. Questo significa che il piano Pro da 20$/mese si esaurisce dopo pochi prompt complessi. L'analisi di QJC su oltre 500 commenti Reddit (marzo 2026) sintetizza efficacemente il sentiment: Claude Code è qualitativamente superiore ma inutilizzabile nei piani base, mentre Codex è leggermente inferiore in qualità ma permette di lavorare senza interruzioni. Numerosi sviluppatori riportano di non aver mai raggiunto il limite del piano Codex da 20$ nemmeno dopo sessioni intensive di sviluppo.
La formula che circola nei forum nel 2026
Due piani da 20$ (Codex + Claude Code) per 40$/mese spesso rendono più della versione Max di Claude a 100$/mese, in termini di produttività effettiva. L'architettura per il lavoro più esigente emersa dalla community: Codex per l'esecuzione quotidiana, Claude Code come strumento secondario per le decisioni architetturali complesse.
Funzionalità: dove Claude Code è genuinamente avanti
È giusto riconoscere dove Claude Code dispone di un vantaggio strutturale reale. Il contesto da 1 milione di token in beta (rispetto ai 400K di Codex) permette di inglobare interi repository complessi in una singola sessione. Il sistema di sub-agent orchestrati (Agent Teams, febbraio 2026) consente di assegnare frontend, backend e test a istanze separate che comunicano tra loro attraverso task list condivise. L'integrazione con MCP è più matura e meno frustrante da configurare rispetto all'esperienza Codex. E il punteggio OSWorld al 72,7% dimostra una capacità superiore nell'interazione con interfacce grafiche e flussi multi-step.
- Contesto fino a 1M token (beta) — ideale per repository di grandi dimensioni
- Agent Teams: sub-agenti paralleli con contesto dedicato
- Integrazione MCP più fluida e meno onerosa da gestire
- Hooks e lifecycle management per workflow avanzati
- Piano mode per revisione pre-esecuzione dei cambiamenti
- Migliori prestazioni su task GUI-adjacent (OSWorld 72,7%)
Dove Codex è genuinamente competitivo
La narrazione che dipinge Codex come uno strumento limitato o superato è semplicemente errata sul piano dei fatti. Codex ha colmato il divario in modo significativo nel 2026. Dispone ora di una desktop app per macOS, integrazione Slack nativa (il modello risponde a @Codex direttamente nei thread), supporto per input visivi (screenshot, wireframe, diagrammi), un SDK completo e supporto multi-agent v2. L'interfaccia CLI, riscritta da TypeScript a Rust nel febbraio 2026, è più veloce e non richiede dipendenze. Il codice sorgente è open source (licenza Apache 2.0), il che permette personalizzazioni profonde e apprendimento dalla base di codice stessa.
Tra fine marzo e inizio aprile 2026 il codice sorgente di Claude Code è stato esposto pubblicamente dopo un leak da parte di un utente che ha trovato i registri del codice sorgente su npm. Non sappiamo se si tratta di una coincidenza o se il team di Anthropic ha preferito appunto rilasciarlo una volta scoperto che il codice sorgente era diventato pubblico.
Sul piano della precisione tecnica, diversi sviluppatori su Reddit e Hacker News documentano una capacità di Codex di intercettare condizioni di race, edge case e errori logici che Claude talvolta manca. Il benchmark Terminal-Bench 2.0, 77,3% contro il 65,4% di Claude, traduce questo in dati oggettivi. Per task di DevOps, scripting e automazione bash, Codex è statisticamente più affidabile.
Un altro aspetto rilevante riguarda la trasparenza dell'esecuzione: Codex mostra in modo più dettagliato e narrativo ciò che sta facendo e perché, anche per chi non conosce a fondo il codebase. Claude Code, al contrario, tende a sintetizzare di più e richiede qualche keystroke aggiuntivo per ottenere la stessa visibilità. Per sviluppatori meno esperti o per team che lavorano su basi di codice non familiari, questa differenza ha un impatto pratico non trascurabile.
Il terzo attore: GPT-5.4 e la qualità del codice sicuro
Un confronto onesto nel 2026 non può ignorare GPT-5.4, che non è soltanto il motore di Codex ma un modello con caratteristiche proprie. Sul fronte della qualità del codice e in particolare del codice sicuro, emergono dati interessanti. Un benchmark condotto da SitePoint su 50 task di sviluppo evidenzia che, in contesti che richiedono TypeScript con strict null checks, Claude produce codice che supera tsc --strict senza modifiche con frequenza maggiore rispetto a GPT-5. Su task di costruzione di query SQL, Claude genera query parametrizzate per default, mentre GPT-5 ha optato per string interpolation in almeno un caso, segnalato dai revisori come potenziale vettore di SQL injection.
Tuttavia, GPT-5.4 presenta vantaggi concreti su altri fronti: la documentazione generata è in media più completa (2,6 punti superiori per task nel benchmark SitePoint), la generazione multi-file è più sistematica (incluse configurazioni, definizioni di tipo e stub di test che Claude omette senza esplicita richiesta) e la velocità di generazione è misurabilmente più alta in sessioni interattive. Sul versante del ragionamento di alto livello, Claude Opus 4.6 mantiene un vantaggio documentato: 91,3% su GPQA Diamond contro un punteggio inferiore non reso pubblico da OpenAI.
Claude è più equilibrato tra i modelli della stessa famiglia: Claude Opus 4.6 e Sonnet 4.6 mantengono una coerenza qualitativa più stabile rispetto alla gamma ChatGPT, dove i modelli economici presentano un divario di qualità più netto rispetto ai modelli flagship. Per un utilizzo quotidiano senza necessità di ricorrere sempre al modello più potente, Claude offre una base più affidabile.
I flussi di lavoro ibridi: la risposta della community
La risposta pratica che emerge dai forum nel 2026 non è una scelta esclusiva tra i due strumenti: è l'orchestrazione intelligente di entrambi. I pattern documentati dalla community sono diversi e convergenti.
Claude Code genera le funzionalità e gestisce le decisioni architetturali. Codex viene invocato in seguito per la revisione del codice prima del merge. Questo sfrutta la capacità di Codex di individuare errori logici e condizioni di race che Claude può aver trascurato. È il workflow più citato su Hacker News tra i team che lavorano su codebase complesse.
Non esiste uno stato dell'arte: entrambi sono in evoluzione
Forse il punto più importante da comprendere nel 2026 è che la narrativa del 'vincitore assoluto' è strutturalmente sbagliata. Il mercato degli strumenti AI per il codice è proiettato a 91 miliardi di dollari entro il 2035, con una crescita annuale del 27,6%. In questo contesto, sia Anthropic che OpenAI trattano gli agenti di sviluppo come il loro principale vettore di crescita. Entrambi i prodotti ricevono aggiornamenti rilevanti ogni poche settimane.
Maggio 2025
Lancio di Claude Code e del nuovo Codex (agente completo, non il modello 2021).
Ottobre 2025
Codex raggiunge la general availability.
Febbraio 2026
OpenAI rilascia GPT-5.3-Codex e la desktop app macOS. Anthropic lancia Claude Opus 4.6 e Sonnet 4.6 con context window da 1M token in beta e Agent Teams.
Marzo 2026
OpenAI rilascia GPT-5.4 Thinking con context window da 1M token e output massimo da 128K. Il mese più competitivo nella storia dei modelli AI secondo diversi analisti.
La convergenza è visibile anche a livello di funzionalità: Codex ha aggiunto supporto MCP e un sistema Skills; Claude Code ha lanciato sessioni cloud sandboxed e agent teams. La direzione è verso un'orchestrazione multi-modello come modalità di lavoro standard, non verso una scelta definitiva tra piattaforme.
Guida alla scelta: quale strumento per quale scenario
Lavoro su repository complessi e decisioni architetturali
Claude Code (Opus 4.6) è la scelta più indicata. Il context window esteso, la capacità di ragionamento multi-step e il punteggio SWE-bench Verified rendono questo strumento superiore per comprendere codebase di grandi dimensioni e produrre refactoring architetturalmente coerenti. È anche il caso in cui la maggiore spesa in token è giustificata dalla complessità del task.
Scripting, DevOps e automazione bash
Codex è la scelta più affidabile. Il punteggio del 77,3% su Terminal-Bench 2.0 non è un dato marginale: su task di scripting, gestione di pipeline CI/CD e automazione da terminale, Codex è statisticamente più preciso e consuma una frazione dei token di Claude Code per lo stesso output.
Frontend e sviluppo UI
Claude Code produce codice UI più idiomatico e meno soggetto a revisioni. Diversi sviluppatori documentano che Codex fatica con React e lavoro frontend, mentre Claude Code gestisce il codice UI con risultati notevolmente migliori. Il punteggio OSWorld al 72,7% vs 64,7% di Codex conferma il vantaggio su task GUI-adjacent.
Code review e intercettazione di bug critici
Codex eccelle nella revisione del codice altrui. La comunità documenta consistentemente la capacità di GPT-5.3-Codex di intercettare errori logici, condizioni di race e edge case che Claude manca su task specifici di debugging terminale. Un workflow diffuso prevede di usare Codex come revisore finale del codice generato da Claude Code prima del merge.
Budget limitato o utilizzo intensivo quotidiano
Codex è la scelta più efficiente. Il consumo di token 4 volte inferiore rispetto a Claude Code rende il piano da 20$ di ChatGPT/Codex molto più utilizzabile in termini pratici. Per chi non può o non vuole investire nei piani premium, Codex offre una produttività reale senza interruzioni da limiti di utilizzo.
Oltre la guerra tra tool
Il dibattito Claude Code vs Codex nei forum del 2026 soffre di due distorsioni simmetriche: da un lato, la sovrastima del vantaggio di Claude Code basata su benchmark non sempre comparabili; dall'altro, la sottovalutazione sistematica di Codex da parte di chi lo ha valutato con strumenti e aspettative dello strumento precedente. La realtà documentata dai dati è che siamo in presenza di due agenti AI di fascia alta, con specializzazioni complementari e un gap qualitativo che sui benchmark più robusti si riduce a meno di due punti percentuali.
Il vantaggio di Claude Code su ragionamento e codebase complesse è documentato. Il vantaggio di Codex su task terminale, efficienza dei token e continuità d'uso è altrettanto documentato. GPT-5.4 aggiunge un terzo polo con caratteristiche proprie — precisione nella documentazione, velocità di generazione, computer use — che rende il quadro ancora più articolato. La combinazione migliore, ad oggi, è quasi certamente avere accesso a entrambi gli ecosistemi e orchestrarli in modo consapevole rispetto al tipo di task. Non è una risposta comoda, ma è quella più onesta.
In sintesi
Claude Code è superiore su: ragionamento complesso, grandi codebase, frontend UI, OSWorld. Codex è superiore su: task terminale, efficienza token, utilizzo intensivo a costo contenuto, code review. GPT-5.4 è superiore su: documentazione automatica, generazione multi-file, computer use. Nessuno dei tre ha raggiunto uno stato dell'arte definitivo: il panorama è in continua evoluzione e i gap si riducono ad ogni aggiornamento.
Sistemi di agenti a confronto: Agent Teams vs sub-agents di Codex
Uno degli aspetti meno analizzati nei confronti superficiali tra i due strumenti riguarda il modo in cui ciascuno gestisce l'orchestrazione multi-agente. Sia Claude Code che Codex dispongono di sistemi di agenti, ma la loro filosofia di funzionamento è sostanzialmente diversa, e confonderli porta a valutazioni errate su entrambi i fronti.
Claude Code — Agent Teams: controllo di alto livello
Il sistema di Agent Teams di Claude Code è progettato per un controllo di alto livello sull'intero ciclo di sviluppo. Il team lead dispone di capacità che non hanno equivalenti diretti in altri strumenti di orchestrazione: può accendere e spegnere agenti in corso d'opera, promuoverli a ruoli diversi, crearne di nuovi dinamicamente e operare uno steering continuo che funziona con notevole affidabilità. L'architettura è pensata per gestire lavori complessi e articolati, dove il contesto deve fluire tra istanze diverse — frontend, backend, testing — attraverso task list condivise e messaggistica diretta tra agenti. È uno strumento di controllo di alto livello, non un amplificatore di velocità pura. Il lato critico è il consumo di risorse: ogni agente attivo erode il budget di contesto e il limite di utilizzo della sessione. Con un piano da 20$/mese e Opus, il sistema può saturarsi in pochi minuti con più agenti su task intensivi.
Codex — sub-agents: amplificatori di velocità
I sub-agents di Codex operano con un approccio radicalmente diverso: più semplificato, più mirato e molto meno invasivo sul budget di sessione. La loro architettura sfrutta sandbox cloud isolate con budget separati per ciascun agente, in modo che un task non eroda le risorse degli altri. Il risultato è che anche una sessione di cinque ore con sub-agents attivi su task paralleli difficilmente arriva a saturare il limite del piano da 20$. Li definisco più correttamente come amplificatori di velocità di sviluppo: eccellono nell'esecuzione parallela di operazioni mirate e isolate — review simultanee su moduli diversi, verifiche di sicurezza compartimentate, test paralleli su varianti di codice. Non gestiscono un progetto nella sua interezza, ma eseguono task definiti in parallelo in modo efficiente, senza overhead di orchestrazione.
La conclusione che emerge dall'utilizzo diretto in produzione di entrambi i sistemi è che non è corretto confrontarli come se fossero due implementazioni della stessa idea. I sub-agents di Codex funzionano meglio per operazioni parallele mirate, in particolare per review e verifiche a più livelli. Gli Agent Teams di Claude Code sono superiori per il controllo di alto livello su progetti complessi, dove si ha necessità di steering continuo, promozione dinamica degli agenti e gestione di flussi articolati tra parti diverse di un codebase. Sono due paradigmi di orchestrazione progettati per risolvere problemi diversi.
La distinzione descritta in questa sezione emerge dall'esperienza diretta di utilizzo in produzione di entrambi i sistemi, non da benchmark ufficiali. I comportamenti sono coerenti con l'architettura dichiarata dai due vendor, ma vanno sempre verificati sul proprio caso d'uso specifico: entrambe le piattaforme aggiornano questi sistemi con frequenza elevata.
Sub-agents e code security: un caso d'uso ad alto valore
Un'applicazione particolarmente efficace dei sub-agents di Codex riguarda la verifica della sicurezza e la qualità del codice. Come già osservato nella sezione dedicata ai benchmark e a GPT-5.4, il modello in modalità xhigh effort tende a produrre codice più conservativo sul piano della sicurezza rispetto a Claude: genera query parametrizzate per default, applica type narrowing corretto in TypeScript e gestisce in modo più sistematico i pattern di input validation. Queste caratteristiche lo rendono un candidato naturale per il ruolo di revisore in pipeline di quality assurance.
Il workflow combinato che emerge dalla pratica prevede di impiegare sub-agents Codex in parallelo per eseguire verifiche a più livelli sul codice prodotto da Claude Code: un agente dedicato alla security review (SQL injection, XSS, validazione degli input), uno alla coerenza dei tipi TypeScript, uno alla copertura dei test. La natura compartimentata e budget-isolata dei sub-agents li rende particolarmente adatti a questo ruolo: operano in parallelo senza saturare la sessione, e la capacità di GPT-5.4 xhigh effort di individuare condizioni di race e edge case si integra in modo complementare con la profondità architettuale di Claude Code.
Pipeline di quality assurance multi-modello
Generazione con Claude Code Opus 4.6 → Review parallela con sub-agents Codex in modalità GPT-5.4 xhigh effort su: sicurezza (injection, XSS, validazione input), type safety TypeScript, copertura test → Merge solo dopo approvazione multi-livello. Questo workflow sfrutta i punti di forza documentati di entrambi gli ecosistemi e produce un livello di quality assurance difficile da replicare con un singolo strumento.
Stack consigliato per sviluppatori Windows + WSL2
Chi lavora su Windows con WSL2 si trova in una posizione interessante per sfruttare entrambi gli strumenti in modo complementare. L'ambiente Linux in WSL2 è nativo abbastanza da far girare Claude Code senza compromessi, mentre Codex, che opera principalmente in cloud, non risente quasi in nessun caso della configurazione locale. Ci sono però alcune accortezze operative che fanno una differenza significativa nella qualità del workflow quotidiano.
Skill di progetto e skill globali: perché AGENTS.md e CLAUDE.md vanno evitati
Sia Claude Code che Codex supportano file di istruzioni persistenti, CLAUDE.md e AGENTS.md rispettivamente, che vengono caricati automaticamente ad ogni sessione. L'intenzione è buona, ma nella pratica questi file creano più problemi di quanti ne risolvano: inquinano il contesto con istruzioni non sempre pertinenti al task in corso, aumentano il consumo di token su ogni prompt e tendono ad accumularsi nel tempo fino a diventare ingestibili.
L'approccio consigliato è non usare AGENTS.md né CLAUDE.md come contenitori di istruzioni generali. Caricano contesto non pertinente ad ogni sessione, consumano token inutilmente e rischiano di creare conflitti con le istruzioni specifiche del task. Questa raccomandazione vale per entrambi gli strumenti.
L'alternativa più efficace è strutturare le istruzioni operative come skill di progetto, da referenziare esplicitamente quando servono, e skill globali a livello utente per le preferenze trasversali. Per ogni progetto conviene creare un file dedicato che descriva: l'approccio architetturale specifico, lo stile di scrittura del codice, i comportamenti attesi dall'agente, le procedure da eseguire sempre (linting, test, formato dei commit), il perimetro di azione (quali file toccare, quali non toccare), e qualsiasi vincolo specifico del progetto. Questo file funziona come un documento di linee guida che l'agente consulta su richiesta esplicita, non come un carico automatico che appesantisce ogni interazione.
Struttura minima di una skill di progetto efficace
Una skill di progetto ben scritta include: tipo di progetto e stack tecnologico, convenzioni di naming e stile del codice, procedure obbligatorie prima del commit (es. tsc --strict, eslint, test), perimetro di azione (directory modificabili, file da non toccare mai), comportamento atteso in caso di ambiguità (chiedere sempre, oppure procedere con il minimo indispensabile), e note specifiche sull'architettura che l'agente deve conoscere per non rompere pattern consolidati.
MCP essenziali per un fullstack developer
Per chi lavora come fullstack developer, due MCP diventano quasi indispensabili: FigmaMCP e ChromeMCP. Il primo permette all'agente di leggere direttamente i file di design da Figma e tradurli in codice con una precisione che la descrizione testuale non può avvicinare. Il secondo, ChromeMCP, è quello che cambia più radicalmente il workflow: consente all'agente di navigare, ispezionare il DOM, eseguire JavaScript, fare screenshot e interagire con l'applicazione in esecuzione senza uscire dalla sessione di sviluppo. Su WSL2, ChromeMCP richiede una configurazione specifica che non è documentata in modo esaustivo dagli strumenti stessi.
ChromeMCP su WSL2: soluzione al problema 'Target closed'
Chi tenta di usare chrome-devtools-mcp con Claude Code in ambiente WSL si scontra quasi inevitabilmente con l'errore 'Protocol error (Target.setDiscoverTargets): Target closed'. La causa è strutturale: il server MCP è progettato per ambienti Linux nativi e non riesce a gestire in modo affidabile il lancio di Chrome attraverso il confine WSL-Windows. Usare il Chrome di Windows da WSL tramite percorso /mnt/c/... o configurare connessioni via --browserUrl su localhost fallisce per via dell'isolamento dei processi e del networking tra i due ambienti.
La soluzione è installare Chrome for Linux direttamente nell'ambiente WSL e configurare il server MCP affinché lo usi. Questo elimina qualsiasi attraversamento del confine WSL-Windows e fa girare tutto nel contesto Linux nativo.
Passo 1 - installare Chrome for Testing in WSL
Nel terminale WSL, eseguire il seguente comando:
L'output mostrerà il percorso completo del binario installato:
Annotare il percorso completo incluso il numero di versione - servirà nel passo successivo.
Passo 2 - aggiornare la configurazione di Claude Code
Aprire il file ~/.claude.json (non il file .codex/config.toml, che riguarda la CLI di Codex e non ha effetto su questo server MCP) e aggiornare la sezione del server chrome-devtools:
Sostituire TUO_USERNAME con il nome utente WSL effettivo e il numero di versione con quello restituito dal comando di installazione. I flag --no-sandbox e --disable-setuid-sandbox sono necessari per far girare Chrome nel contesto di sicurezza di WSL e non possono essere omessi.
Passo 3 - riavviare Claude Code e verificare
Chiudere e riaprire Claude Code completamente - i server MCP vengono inizializzati all'avvio e le modifiche alla configurazione non hanno effetto su sessioni già aperte. Verificare il funzionamento con qualsiasi tool chrome-devtools:
Problemi comuni e soluzioni
Errore 'Target closed' persiste dopo il riavvio
Verificare che Claude Code sia stato chiuso completamente e non solo minimizzato. I server MCP vengono inizializzati una sola volta all'avvio. Se il problema persiste, controllare che il percorso al binario Chrome nella configurazione corrisponda esattamente - incluso il numero di versione - al percorso restituito dal comando di installazione.
Chrome headless e salvataggio screenshot
Il comportamento predefinito è headless (nessuna finestra visibile). Per visualizzare Chrome: rimuovere il flag --headless dalla configurazione se presente. Su Windows 11 con WSL2, WSLg è incluso nativamente e non richiede configurazione aggiuntiva. Su Windows 10 è necessario un server X11 esterno come VcXsrv. Per salvare gli screenshot in una directory specifica usare il parametro filename: mcp__chrome-devtools__take_screenshot({ filename: "/percorso/desiderato/screen.png" }).
Soluzioni che non funzionano in WSL2: usare Chrome per Windows tramite /mnt/c/Program Files/..., connettersi via --browserUrl=http://localhost:9222 a un'istanza Chrome avviata manualmente, configurare port forwarding con netsh, modificare .codex/config.toml (riguarda la CLI di Codex, non il server MCP). Nessuna di queste opzioni risolve il problema strutturale dell'isolamento tra WSL e Windows.
Configurazione verificata su: Windows 11 con WSL2 (Ubuntu), chrome-devtools-mcp 0.8.1, Claude Code 2.0.20 o superiore, Node 22.x. Node 20 non è supportato.
Grazie per aver letto questo articolo